Machine Learning Productivity Hacks
Struggling to find time to fit everything in while finishing my master’s thesis, a friend lent me a copy of Edmond Lau’s The Effective Engineer. I didn’t find the extra hour a day to watch Netflix read papers that I was hoping for, but the book did have an impact on my research workflow.
One of my main takeaways from the book was the importance of investing in iteration speed. Always be looking for things you’re doing often that you could speed up or automate entirely by making a tool. Quoting Lau:
Bobby Johnson, a former Facebook Director of Infrastructure Engineering, told me, I’ve found that almost all successful people write a lot of tools … [A] very good indicator of future success [was] if the first thing someone did on a problem was to write a tool.
(OK, there’s some implicit logic I don’t agree with here in using this quote to suggest you should write more tools, but the quote’s at least made the idea stick in my mind.)
Here’s a quick look at some tools I’ve found helpful in my machine learning engineering work.
Grab remote files with iTerm2 triggers
You know when you’re monitoring a run on a remote server, and you want to quickly grab a file - say, a video? You make a note of the remote path, open up another terminal, use something like rsync to transfer it across, switch to a file browser, and finally navigate to where you put it. Do it for a few different runs, and it gets tedious real quick.
(SSHFS might work for some folks, but I’ve never been able to get it to run well enough on macOS.)
What you really want is to navigate to the file on the remote server, then bam, have it magically appear on your local machine. It turns out this is totally possible.
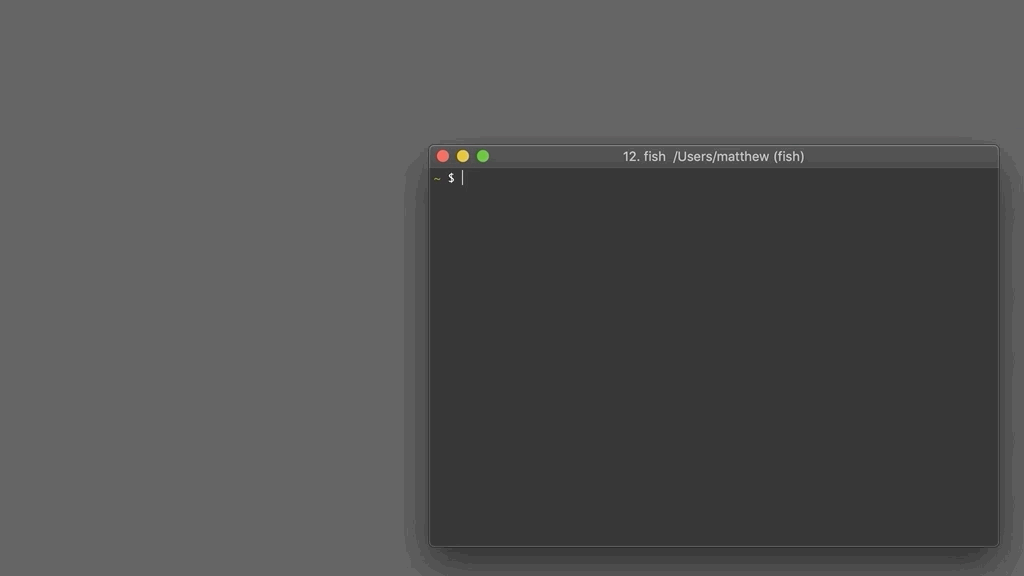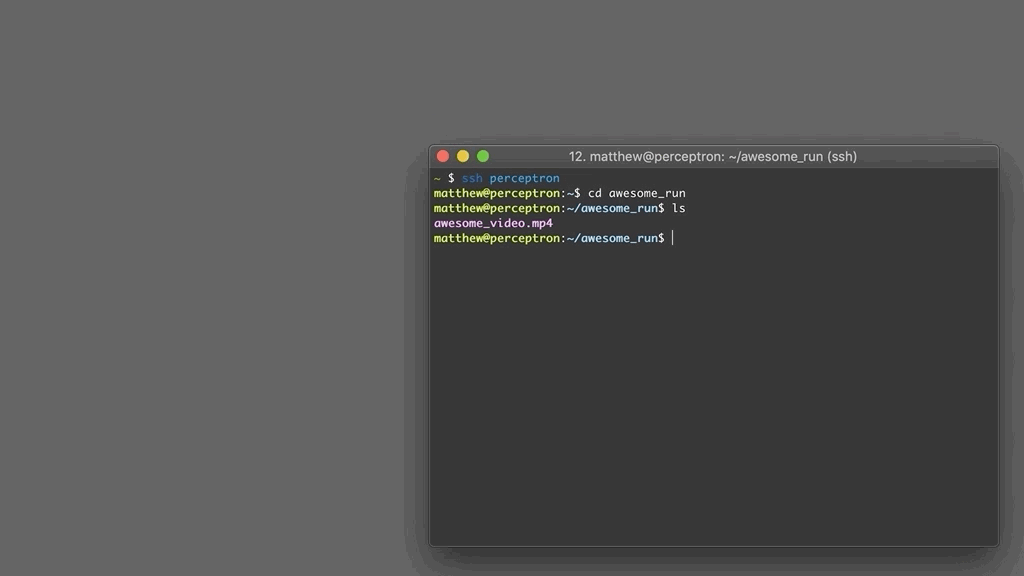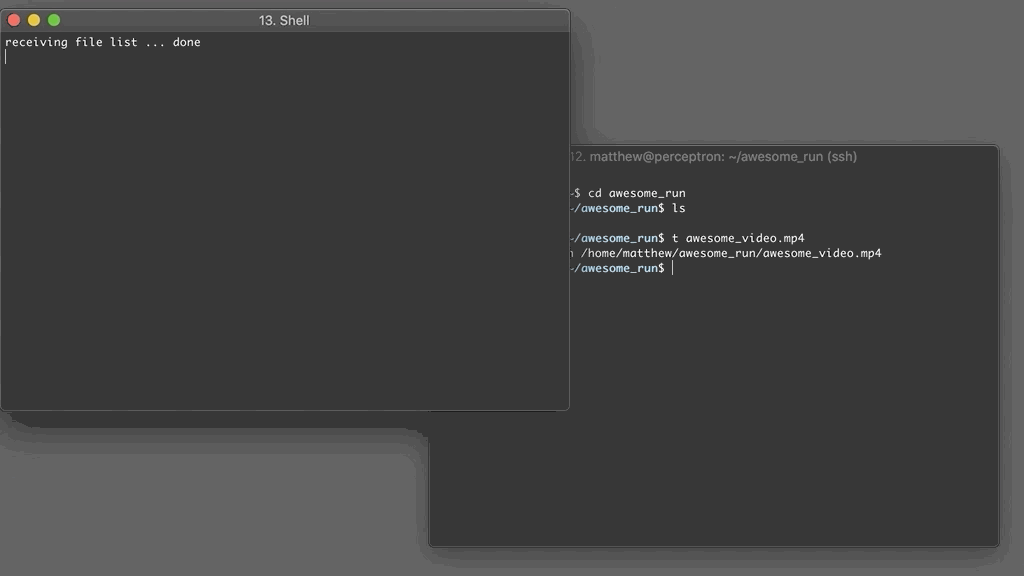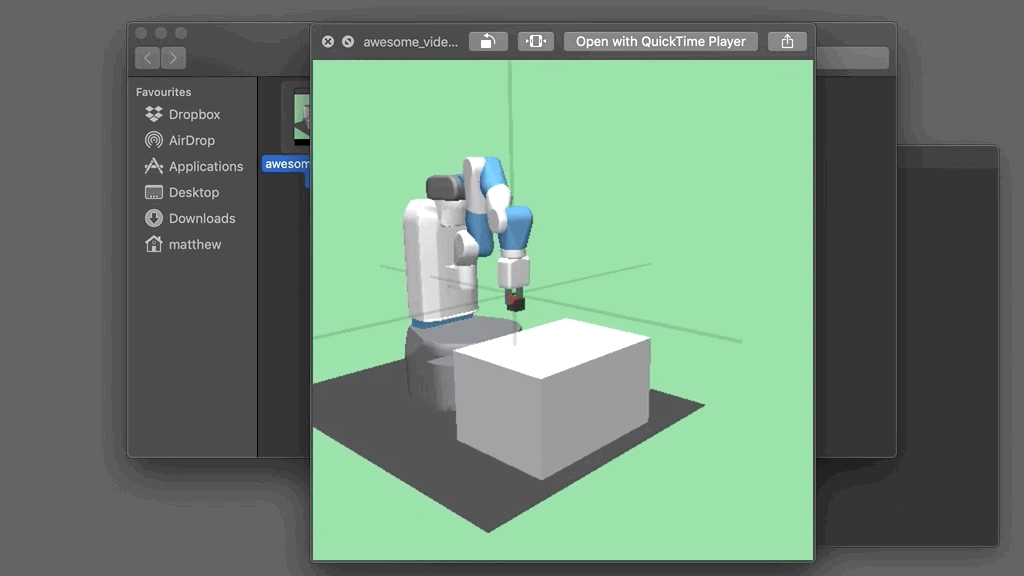
What’s going on here? It turns out there’s a great feature in iTerm2: the terminal can watch out for a specific trigger string and execute a command in response.
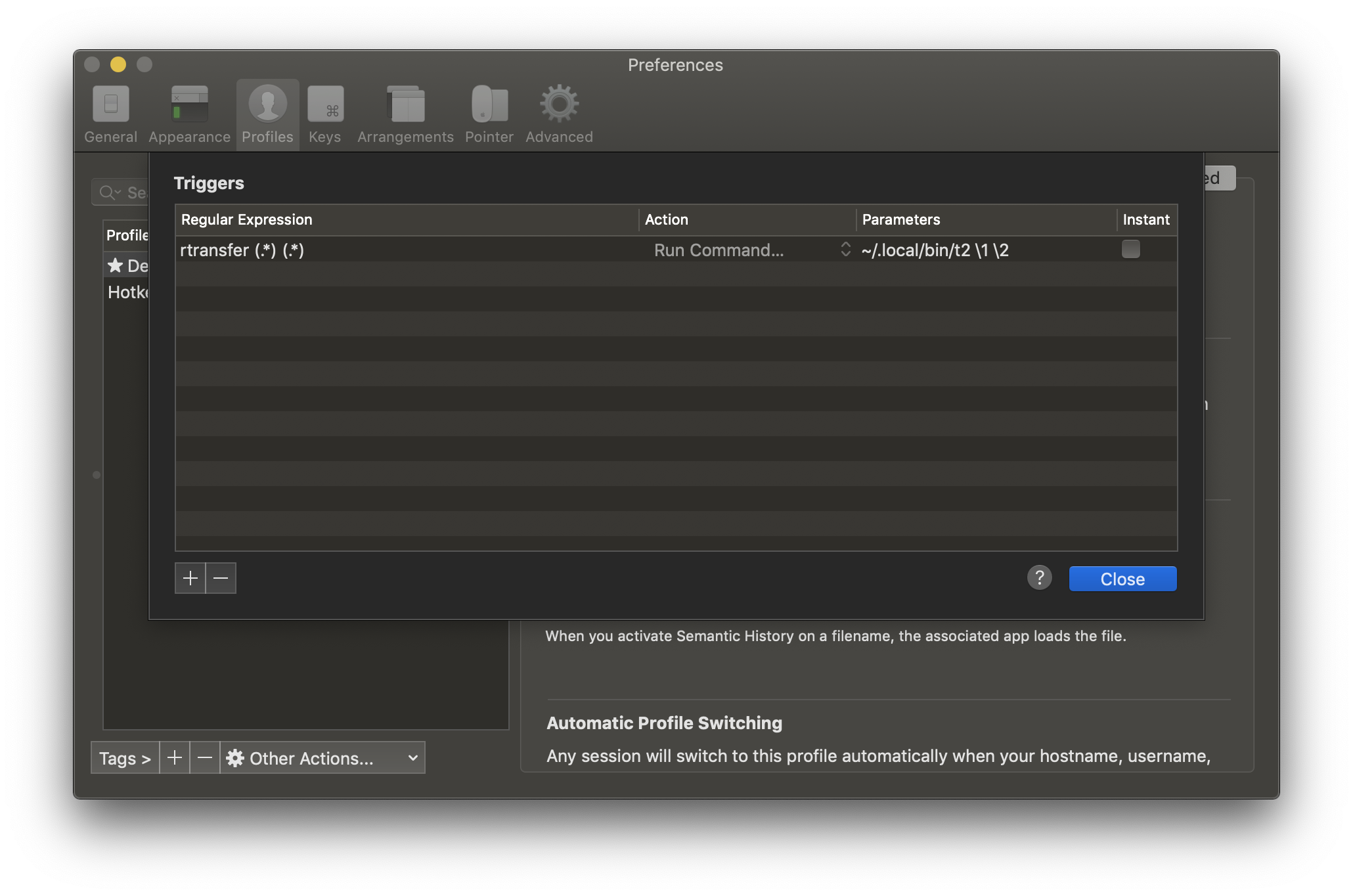
So here, I have a script t on the remote server. When executed, it prints out the string rtransfer <host> <path>. iTerm2 picks up on rtransfer as a trigger string, parses out the host and path, then invokes another script on my local machine, t2. The script transfers the file to a temporary directory then opens Finder at that location.
You can imagine variations on this. For example, checking videos is something I do a lot, so I use another script, tnv, which automatically transfers the five most recent videos from a given directory.
Tailor your scripts to whatever you spend the most time on.
Use ngrok to access remote TensorBoard
Another real pain can be accessing TensorBoard instances on remote servers. You set up SSH port forwarding…oh, but which port was it for which server? And oh, this one’s in a Docker container…
ngrok lets you get around this by making local ports accessible at a publicly-accessible URL. You just run ngrok http 6006 and gives you a URL like http://683acac3.ngrok.io which you shows shows TensorBoard instance.
Combined with a couple of helpers - n, to start ngrok faster, an iTerm trigger to open a web browser, and tb, which starts TensorBoard then once it’s ready calls n - you can get from run directory to graphs in under ten seconds.
(One difficulty with ngrok is that it only allows one session at a time. If you forget to kill ngrok on the last server, it can be annoying to figure out where you left it running. In practice, I’ve actually reverted back to SSH forwarding for most servers, but again with an iTerm trigger and a couple of helper scripts which find a forward a free port automatically.)
Plot graphs with tbplot instead of TensorBoard
For runs with a lot of metrics, the bottleneck is often just waiting for TensorBoard to load all the graphs (and if you’re keeping detailed logs, then taking screenshots of all those graphs).
Instead, consider using tbplot, which plots graphs using Matplotlib (though currently only scalar graphs). It’s much, much faster, and produces image files directly.
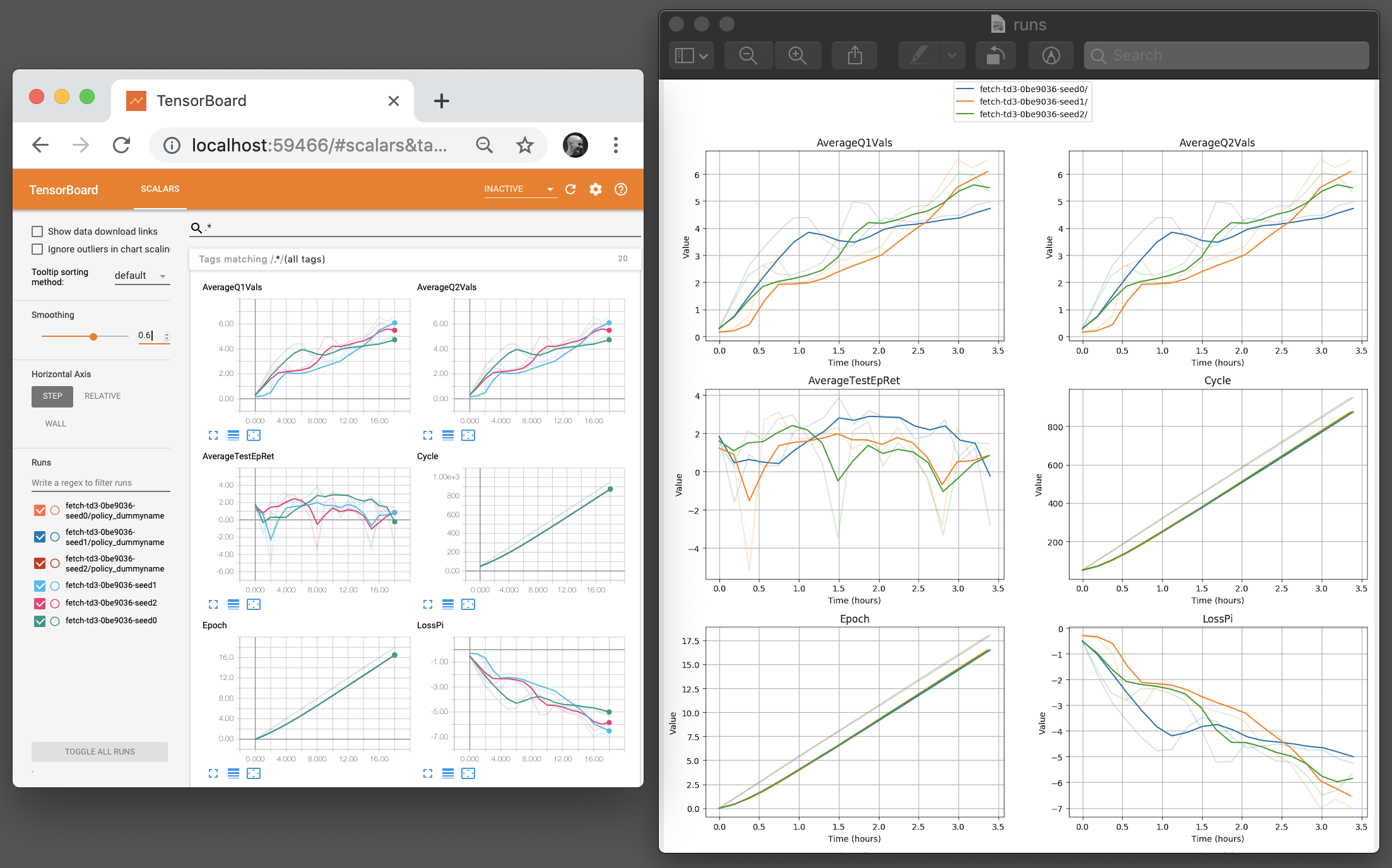
Automate crash monitoring
Automation isn’t just about saving time - it’s also about saving energy.
When doing a lot of runs while iterating on potentially-buggy code, the most draining thing is worrying that one of them has hit a bug and crashed, feeling a constant need to check how they’re doing.
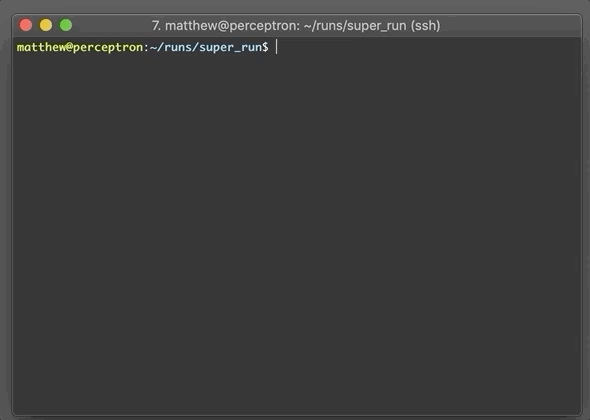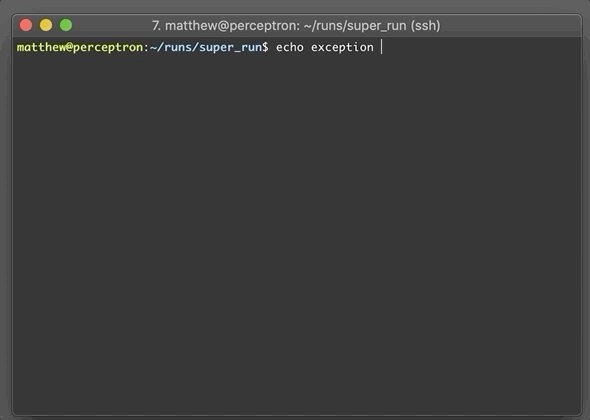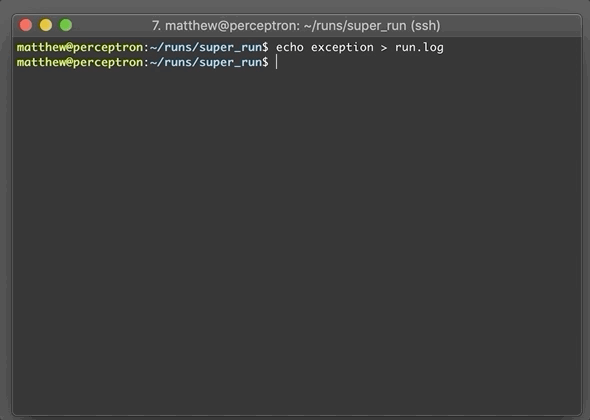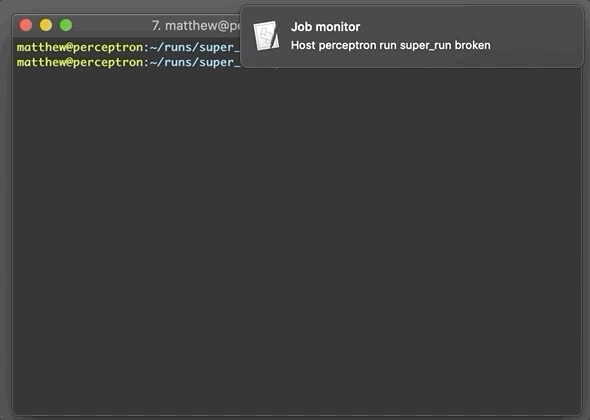
Automating monitoring with alerts when something does go wrong does a lot to soothe that worry. To avoid needing to have Slack or an email client open, I use sqs-alerts, which stores and receives messages using an AWS Simple Queue Service. On each remote machine I run a script every so often with cron that monitors logs and sends a message to the queue if it detects a run is broken. On my local machine I then run a service which monitors the queue and pops up an alert when a message is received.
Conclusions
Between iTerm triggers for checking videos and saving graphs using tbplot, I’d guess I save around 15 minutes a day.
But more important than time saved is how much less friction there now is in my workflow. I don’t have to dread checking runs every day knowing I’m going to have to slog through selecting files and copy-pasting URLs. I think I also focus better: I don’t have to switch between ‘thinking’ mode and ‘finding data’ mode.
I’m curious how other people deal with the day-to-day problems of iterating quickly on e.g. reinforcement learning research code. If you have any suggestions, do leave a comment!