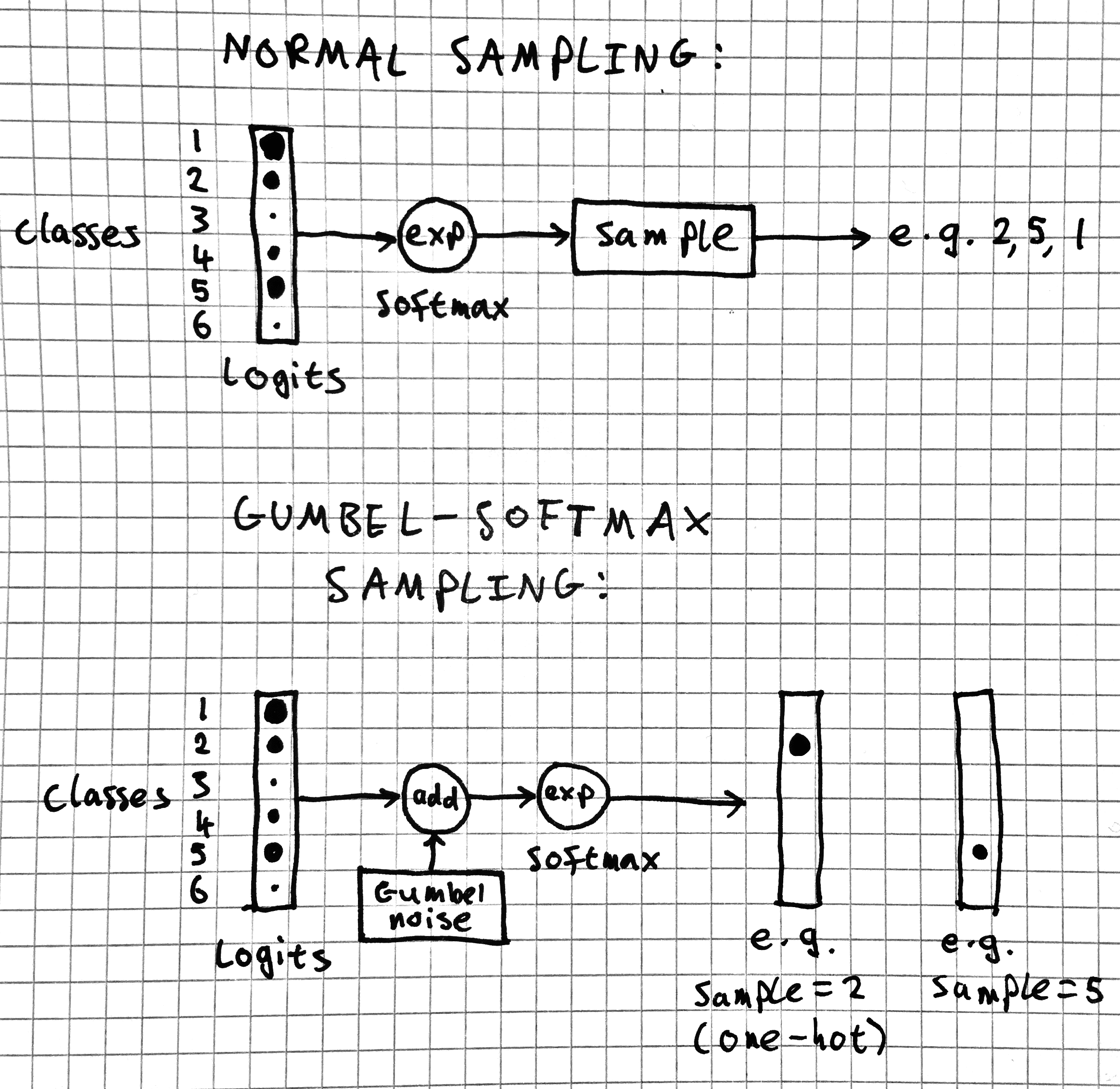
A few weeks ago, I was looking through OpenAI's implementation of A2C. The final step in A2C is to generate an action for the agent by sampling from a categorical probability distribution over possible discrete actions. Usually, I've done this with np.random.choice, but OpenAI's implementation was doing it a completely different way. Looking at utils.py, we have:
def sample(logits):
noise = tf.random_uniform(tf.shape(logits))
return tf.argmax(logits - tf.log(-tf.log(noise)), 1)
This sort of makes sense. If you just take the argmax of the logits, you would always just sample the highest-probability action. So instead, you add some noise to the logits to make things more random, and then take the argmax. But why not just use noise? Why -tf.log(-tf.log(noise))?
There's another strange thing. Usually we sample from the distribution created by passing the logits through a softmax function. If we sample using noise on only the logits, does it give the same results?
It turns out this is a clever way of sampling directly from softmax distribution using noise from a special distribution: the Gumbel distribution. Let's explore what this humble distribution is all about.
(If you'd like to follow along with this notebook interactively, sources can be found at GitHub.)
The Gumbel distribution¶
The Gumbel distribution is a probability distribution with density function
$$p(x) = \frac{1}{\beta} exp(-z - exp[-z])$$ where $$z = \frac{x - \mu}{\beta}.$$
On its own, the Gumbel distribution is typically used to model the maximum of a set of independent samples. For example, let's say you want to quantify how much ice cream you eat per day. Assume your hunger for ice cream is normally-distributed, with a mean of 5/10. You record your hunger 100 times a day for 10,000 days. (We also assume your hunger is erratic enough that all samples are independent.) You make a note of the maximum hunger you experience every day.
The distribution of daily maximum hunger would then follow a Gumbel distribution.
from scipy.optimize import curve_fit
mean_hunger = 5
samples_per_day = 100
n_days = 10000
samples = np.random.normal(loc=mean_hunger, size=(n_days, samples_per_day))
daily_maxes = np.max(samples, axis=1)
def gumbel_pdf(prob, loc, scale):
z = (prob - loc) / scale
return exp(-z - exp(-z)) / scale
def plot_maxes(daily_maxes):
probs, hungers, _ = hist(daily_maxes, normed=True, bins=100)
xlabel("Hunger")
ylabel("Probability of hunger being daily maximum")
(loc, scale), _ = curve_fit(gumbel_pdf, hungers[:-1], probs)
plot(hungers, gumbel_pdf(hungers, loc, scale))
figure()
plot_maxes(daily_maxes)

From what I understand[1], the Gumbel distribution should be a good fit when the underlying data is distributed according to either a normal or an exponential distribution. To convince ourselves, let's try again with exponentially-distributed hunger:
most_likely_hunger = 5
samples = np.random.exponential(scale=most_likely_hunger,
size=(n_days, samples_per_day))
daily_maxes = np.max(samples, axis=1)
figure()
plot_maxes(daily_maxes)

Sure enough, the distribution of maximum daily hunger values is still Gumbel-distributed.
Edit: Varun Sudarsanan points out that for exponential distributions, some adjustment has to be done for the sample size. This doesn't show up here because the sample size is only 100, but it becomes more relevant the larger the sample size. Thanks, Varun!
The Gumbel-max trick¶
What does the Gumbel distribution have to do with sampling from a categorical distribution?
To experiment, let's set up a distribution to work with.
n_cats = 7
cats = np.arange(n_cats)
probs = np.random.randint(low=1, high=20, size=n_cats)
probs = probs / sum(probs)
logits = log(probs)
def plot_probs():
bar(cats, probs)
xlabel("Category")
ylabel("Probability")
figure()
plot_probs()

As a sanity check, let's try sampling with np.random.choice. Do we get the right probabilities?
n_samples = 1000
def plot_estimated_probs(samples):
n_cats = np.max(samples) + 1
estd_probs, _, _ = hist(samples,
bins=np.arange(n_cats + 1),
align='left',
edgecolor='white',
normed=True)
xlabel("Category")
ylabel("Estimated probability")
return estd_probs
def print_probs(probs):
print(" ".join(["{:.2f}"] * len(probs)).format(*probs))
samples = np.random.choice(cats, p=probs, size=n_samples)
figure()
subplot(1, 2, 1)
plot_probs()
subplot(1, 2, 2)
estd_probs = plot_estimated_probs(samples)
tight_layout()
print("Original probabilities:\t\t", end="")
print_probs(probs)
print("Estimated probabilities:\t", end="")
print_probs(estd_probs)

def sample(logits):
noise = tf.random_uniform(tf.shape(logits))
return tf.argmax(logits - tf.log(-tf.log(noise)), 1)
We had some intuition that maybe this works by just using some noise to "shake up" the argmax.
Will any noise do? Let's try a couple of different types.
Uniform noise¶
def sample(logits):
noise = np.random.uniform(size=len(logits))
sample = np.argmax(logits + noise)
return sample
samples = [sample(logits) for _ in range(n_samples)]
figure()
subplot(1, 2, 1)
plot_probs()
subplot(1, 2, 2)
estd_probs = plot_estimated_probs(samples)
tight_layout()
print("Original probabilities:\t\t", end="")
print_probs(probs)
print("Estimated probabilities:\t", end="")
print_probs(estd_probs)

So uniform noise seems to capture the modes of the distribution, but distorted. It also completely misses out all the other categories.
Normal noise¶
def sample(logits):
noise = np.random.normal(size=len(logits))
sample = argmax(logits + noise)
return sample
samples = [sample(logits) for _ in range(n_samples)]
figure()
subplot(1, 2, 1)
plot_probs()
subplot(1, 2, 2)
estd_probs = plot_estimated_probs(samples)
tight_layout()
print("Original probabilities:\t\t", end="")
print_probs(probs)
print("Estimated probabilities:\t", end="")
print_probs(estd_probs)

So normal noise seems to do a better job of capturing the full range of categories, but still distorts the probabilities.
We're getting closer, though. Maybe there's a special kind of noise that gives the right results?
It turns out the 'special kind of noise' happens to be noise from a Gumbel distribution!
Gumbel noise¶
def sample(logits):
noise = np.random.gumbel(size=len(logits))
sample = argmax(logits + noise)
return sample
samples = [sample(logits) for _ in range(n_samples)]
figure()
subplot(1, 2, 1)
plot_probs()
subplot(1, 2, 2)
estd_probs = plot_estimated_probs(samples)
tight_layout()
print("Original probabilities:\t\t", end="")
print_probs(probs)
print("Estimated probabilities:\t", end="")
print_probs(estd_probs)

With Gumbel noise, we get exactly the right probabilities! (At least, similarly as close to the original probabilities as we got by sampling with np.random.choice.)
Note that we get the probabilities despite the fact that we were operating on the logits - not on the post-softmax probabilities themselves.
Why is it that Gumbel noise happens to be exactly the right kind of noise to make this work? Sadly, I haven't been able to come up with an intuitive explanation for why this is the case. If you're into proofs, though, the Harvard Intelligent Probabilistic Systems Group do have something easy-to-follow at The Gumbel-Max Trick for Discrete Distributions.
Generating Gumbel noise¶
What if we only had access to a uniform noise generator? It turns out we can still generate Gumbel noise by starting with uniform noise and then taking the negative log twice. This is exactly what we see in OpenAI's code.
numpy_gumbel = np.random.gumbel(size=n_samples)
manual_gumbel = -log(-log(np.random.uniform(size=n_samples)))
figure()
subplot(1, 2, 1)
hist(numpy_gumbel, bins=50, normed=True)
ylabel("Probability")
xlabel("numpy Gumbel")
subplot(1, 2, 2)
hist(manual_gumbel, bins=50, normed=True)
xlabel("Gumbel from uniform noise");

Why sample with Gumbel noise?¶
Sampling this way is called the Gumbel-max trick.
If all you care about is drawing samples, it's not clear to me why you'd use the Gumbel-max trick rather than np.random.choice (or e.g. tf.multinomial). One neat thing pointed out by Tim Vieira is that if you precompute the noise, Gumbel-max sampling can be a lot faster than the traditional method of sampling. But in cases where sampling speed isn't a bottleneck, I don't think the tradeoff in readability is worth it.
However, it turns out that with a little more work, we can do something really interesting with the Gumbel-max trick.
The Gumbel-softmax trick¶
Remember, the Gumbel-max trick produces a sample by adding noise to the logits then taking the argmax of the resulting vector. So far, there's nothing so special about Gumbel-max sampling.
But what if we approximate the argmax by a (low-temperature) softmax? Then something really interesting happens: we have a chain of operations that's fully differentiable. We have differentiable sampling operator (albeit with a soft one-hot output instead of a scalar). Wow!
Update: asobolev points out in the reddit comments that you can convert the soft one-hot representation to a scalar by taking a dot product with the choice indices. Neat!
TensorFlow example¶
Let's convince ourselves that this really works with a quick example. (For simplicity, we ignore the temperature of the softmax so we get a very soft one-hot representation of the sample.)
import tensorflow as tf
sess = tf.Session()
def differentiable_sample(logits):
noise = tf.random_uniform(tf.shape(logits))
logits_with_noise = logits - tf.log(-tf.log(noise))
return tf.nn.softmax(logits_with_noise)
Let's set up a normal distribution parameterised by some variable representing the mean.
mean = tf.Variable(2.)
idxs = tf.Variable([0., 1., 2., 3., 4.])
# An unnormalised approximately-normal distribution
logits = tf.exp(-(idxs - mean) ** 2)
sess.run(tf.global_variables_initializer())
def print_logit_vals():
logit_vals = sess.run(logits)
print(" ".join(["{:.2f}"] * len(logit_vals)).format(*logit_vals))
print("Logits: ", end="")
print_logit_vals()
Let's sample from this distribution, then calculate a value based on the sample such that higher samples give larger results.
sample = differentiable_sample(logits)
sample_weights = tf.Variable([1., 2., 3., 4., 5.], trainable=False)
result = tf.reduce_sum(sample * sample_weights)
Finally, let's use gradient descent to try and maximize that final value. Since we get larger values for higher samples, we expect the mean of the distribution to shift upwards.
sess.run(tf.global_variables_initializer())
train_op = tf.train.GradientDescentOptimizer(learning_rate=1).minimize(-result)
print("Distribution mean: {:.2f}".format(sess.run(mean)))
for i in range(5):
sess.run(train_op)
print("Distribution mean: {:.2f}".format(sess.run(mean)))
It worked! We were able to back-propagate all the way to the parameter of the distribution.
When is the Gumbel-softmax trick useful?¶
In general, the Gumbel-softmax trick is interesting whenever we're in the following situation:
- We have logits computed using some parameters
- Those logits are converted to a probability distribution
- We take a sample from the distribution
- We have some downstream effect (e.g. a loss) that's calculated based on the sample
- We want to calculate how to change the parameters in order to change the downstream effect
In short, Gumbel-softmax is interesting whenever we want gradients of something downstream of sampling.
(It's interesting to compare this to the usual setup for supervised learning for classification. There, loss is calculated based on cross-entropy between the predicted distribution over class labels and a one-hot vector representing the correct class label. In contrast to the situation described above, in classification, the loss is calculated based on the probability distribution itself, rather than on a sample from the distribution.)
Gumbel-softmax in the wild: reinforcement learning¶
Bringing us full-circle back to reinforcement learning, for an example of the Gumbel-softmax trick used in the real world, we can take a quick look at OpenAI's recent Learning to Communicate paper.
Their setup involved multiple agents cooperating to achieve shared goals. The agents communicate their goals to each other (e.g. "Look at the green landmark") through a simple language which develops during training.
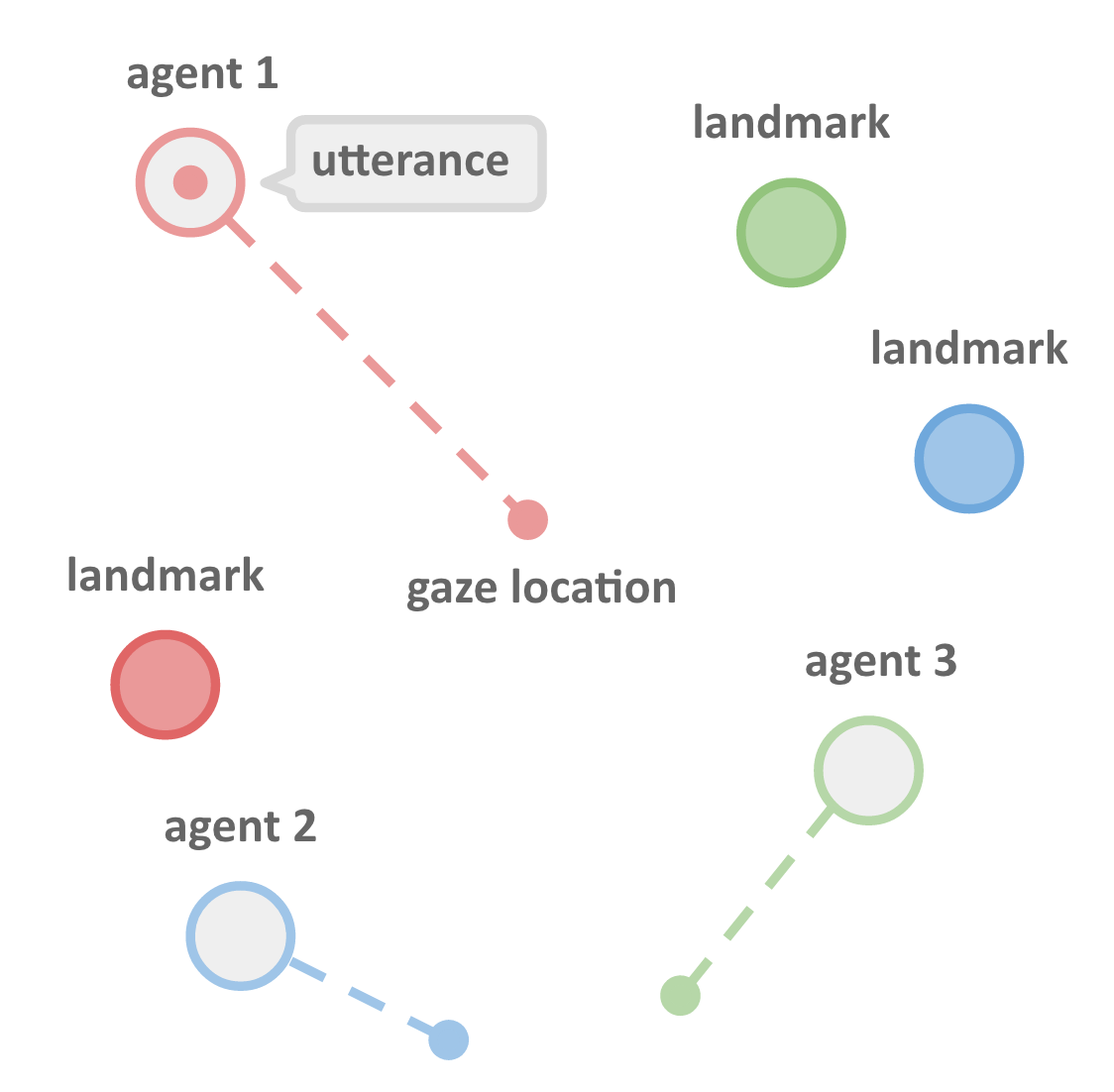 Image source: Learning to Communicate
Image source: Learning to Communicate
Words in the language are sampled from a probability distribution that's a function of what each agent sees. Using the Gumbel-softmax trick meant that sampling of words was differentiable, and therefore so was the whole communication channel. With a differentiable communication channel, they were able to calculate how each agent should change what it said in order for all agents to achieve better reward.
This is a really exciting thing to be able to do. More generally, having a differentiable means of sampling actions, and therefore being able to back-propagate through other agents' actions - this could open the gates for a whole bunch of new possibilities in cooperative reinforcement learning. OpenAI's blog post notes that there are other ways to do it, but the Gumbel-softmax trick just makes it so easy.
Summary¶
We've taken a look at the Gumbel distribution, the Gumbel-max trick for generating samples, and the Gumbel-softmax trick for differentiable sampling.
If you'd like to read more, there are two main papers which seem to be responsible for revitalising interesting in the various Gumbel tricks. You'll find lots of details there:
- Jang, Gu and Poole's Categorical Reparameterization with Gumbel-Softmax (with a summary at Tutorial: Categorical Variational Autoencoders using Gumbel-Softmax)
- Maddison, Mnih and Teh's The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables